[WIP] The Algorithm Design Manual - Notes
— notes — 36 min read
Pet Peeve: The author sometimes skips steps without an explaination (like the integer truncation in "stop and think: incremental correctness"). Some examples are hard to follow for an international student (like understanding the lottery system in "war story: pschic modeling").
Chapter 1: Introduction to Algorithm Design
A computational problem is a specification of a desired input-output relationship. e.g.
Computational problem: Sorting
Input: A sequence of values , ..., .
Output: The permutation (reordering) of the input sequence such that ... .
An instance of a problem is all the inputs needed to compute a solution to the problem. Alternatively, a computational problem is the set of all (problem) instances and the desired output. e.g.
To sort the permutation
{8, 3, 6, 7}is an instance of the general sorting problem and{3, 6, 7, 8}is the desired output.
An algorithm is a well-defined computational procedure that halts with a desired output when given any instance of the given computational problem. An algorithm is an abstract (idea) and can have multiple implementations (programs). e.g.
1/*2Insertion sort is an algorithm to the sorting problem: Start with a single3element (thus forming a trivially sorted list) and then incrementally inserts4the remaining elements so that the list stays sorted.5*/6insertion_sort(item s[], int n)7{8 int i,j; /* counters */9 for (i=0; i<n; i++) {10 j=i;11 12 while ((j>0) && (s[j] < s[j-1])) {13 swap(&s[j],&s[j-1]);14 j = j-1;15 }16 }17}Modeling the problem
Real-world applications involve real-world objects. However, most algorithms are designed to work on rigorously defined abstract structures. Modeling is the art of formulating your application in terms of procedures on such fundamental abstract structures so as to exploit the existing algorithms literature.
Determining that you are dealing with an instance of a general problem allows you to solve it using general well-known algorithms.
Certain problems can be modeled in several different ways, some much better than others. Modeling is only the first step in designing an algorithm for a problem. Be alert but not dismissive for how the details of your applications differ from a candidate model.
Combinatorial Objects
- Permutations are arrangements, or orderings, of items. E.g:
{1,4,3,2}and{4,3,2,1}are two distinct permutations of the same set of four integers. - Subsets represent selections from a set of items. E.g:
{1,3,4}and{2}are two distinct subsets of the first four integers. Order does not matter in subsets the way it does with permutations. - Trees represent hierarchical relationships between items.
- Graphs represent relationships between arbitrary pairs of objects.
- Points define locations in some geometric space.
- Polygons define regions in some geometric spaces.
- Strings represent sequences of characters, or patterns.

Recursive Objects
Learning to think recursively is learning to look for big things that are made from smaller things of exactly the same type as the big thing.
If you think of houses as sets of rooms, then adding or deleting a room still leaves a house behind.
- Permutations: Delete the first element of a permutation of
nthings{1, ..., n}and you get a permutation of the remainingn-1things. Basis case: {} - Subsets: Every subset of
{1, ..., n}contains a subset of(1, ..., n - 1)obtained by deleting elementn. Basis case: {} - Trees: Delete the root of a tree and you get a collection of smaller trees. Delete any leaf of a tree and you get a slightly smaller tree. Basis case: 1 vertex.
- Graphs: Delete any vertex from a graph, and you get a smaller graph. Now divide the vertices of a graph into two groups, left and right. Cut through all edges that span from left to right, and you get two smaller graphs, and a bunch of broken edges. Basis case: 1 vertex.
- Point sets: Take a cloud of points, and separate them into two groups by drawing a line. Now you have two smaller clouds of points. Basis case: 1 point.
- Polygons: Inserting any internal chord between two non-adjacent vertices of a simple polygon cuts it into two smaller polygons. Basis case: triangle.
- Strings: Delete the first character from a string, and you get a shorter string. Basis case: empty string.
Recursive descriptions of objects require both decomposition rules and basis cases, namely the specification of the smallest and simplest objects where the decomposition stops.

An algorithmic problem is specified by describing the complete set of instances it must work on and of its output after running on one of these instances.
There is a distinction between a general problem and an instance of a problem. E.g:
Problem: Sorting
Input: A sequence ofnkeys a1,...,an.
Output: The permutation (reordering) of the input sequence such that: a′1 ≤ a′2 ≤ ··· ≤ a′n−1 ≤ a′n.
Instance of sorting problem: { Mike, Bob, Sally}; { 154, 245 }
An algorithm is a procedure that takes any of the possible input instances and transforms it to the desired output.
Three desirable properties for a good algorithm:
- Correct
- Efficient
- Easy to implement
Insertion sort is an algorithm to the sorting problem: English description:
Start with a single element (thus forming a trivially sorted list) and then incrementally inserts the remaining elements so that the list stays sorted.
Pseudocode:
1array = input sequence2n = array size3i = 045while i < n6 j = i7 while j > 0 AND array[j] < array[j - 1]8 swap element at `j` with element at `j - 1` in array9 decrement j by 110 increment i by 1Code:
An animation of the logical flow of this algorithm on a particular instance (the letters in the word
“INSERTIONSORT”)
Robot Tour Optimization
Problem: Robot Tour Optimization (aka: Traveling Salesman Problem [TSP]).
Input: A setSofnpoints in the plane.
Output: What is the shortest cycle tour that visits each point in the setS?
Nearest-neighbor heuristic

- English Description:
Starting from some point
p0, we walk first to its nearest neighborp1Fromp1, we walk to its nearest unvisited neighbor. Repeat this process until we run out of unvisited points After which we return top0to close off the tour. - Pseudocode:1NearestNeighbor(P)2 Pick and visit an initial point p₀ from P3 p = p₀4 i = 056 While there are still unvisited points7 i = i + 18 Select pᵢ to be the closest unvisited point to pᵢ₋₁9 Visit pᵢ10 Return to p₀ from pₙ₋₁
- Pros:
- Easy to understand & implement
- Reasonably efficient
- Cons: It's wrong — It always finds a tour, but it doesn’t necessarily find the shortest possible tour.
E.g: A bad instance for the nearest-neighbor heuristic (top) & the optimal solution (bottom):

Closest-pair heuristic
- English description:
Repeatedly connect the closest pair of endpoints whose connection will not create a problem, such as premature termination of the cycle. Each vertex begins as its own single vertex chain. After merging everything together, we will end up with a single chain containing all the points in it. Connecting the final two endpoints gives us a cycle. At any step during the execution of this closest-pair heuristic, we will have a set of single vertices and vertex-disjoint chains available to merge.
- Pseudocode:
Reasoning about Correctness
Correct algorithms usually come with a proof of correctness, which is an explanation of why we know that the algorithm must take every instance of the problem to the desired result.
- We need tools to distinguish correct algorithms from incorrect ones, the primary one of which is called a
proof. - A proper mathematical proof consists of several parts:
- A clear, precise statement of what you are trying to prove.
- A set of assumptions of things that are taken to be true, and hence can be used as part of the proof.
- A chain of reasoning that takes you from these assumptions to the statement you are trying to prove.
- A little square (■) or
QEDat the bottom to denote that you have finished, representing the Latin phrase for "thus it is demonstrated."
- A proof is indeed a demonstration. Proofs are useful only when they are honest, crisp arguments that explain why an algorithm satisfies a non-trivial correctness property.
Problems and Properties
- It is impossible to prove the correctness of an algorithm for a fuzzily-stated problem.
- Problem specifications have two parts:output.1* The set of allowed input instances.2* The required properties of the algorithm's
- An important technique in algorithm design is to narrow the set of allowable instances until there is a correct and efficient algorithm. For example, we can restrict a graph problem from general graphs down to trees, or a geometric problem from two dimensions down to one.
- There are two common traps when specifying the output requirements of a
problem:1* Asking an ill-defined question. E.g: Asking for the best route between two places on a map is a silly question, unless you define what best means.2* Creating compound goals. E.g: A goal like find the shortest route from **a** to **b** that doesn't use more than twice as many turns as necessary is perfectly well defined, but complicated to reason about and solve.
Expressing Algorithms
- The heart of any algorithm is an idea. If your idea is not clearly revealed when you express an algorithm, then you are using too low-level a notation to describe it.
- The three most common forms of algorithmic notation are
- English
- Pseudocode (a programming language that never complains about syntax errors)
- A real programming language.
- All three methods are useful because there is a natural tradeoff between greater ease of expression and precision.
Demonstrating Incorrectness
- The best way to prove that an algorithm is incorrect is to produce a counter example, i.e: an instance on which it yields an incorrect answer.
- Good counterexamples have two important properties:
- Verifiability: To demonstrate that a particular instance is a counterexample to a particular algorithm, you must be able to:
- calculate what answer your algorithm will give in this instance, and
- display a better answer so as to prove that the algorithm didn't find it.
- Simplicity - Good counter-examples have all unnecessary details stripped away. They make clear exactly why the proposed algorithm fails. Simplicity is important because you must be able to hold the given instance in your head in order to reason about it.
- Verifiability: To demonstrate that a particular instance is a counterexample to a particular algorithm, you must be able to:
Induction and Recursion
- Recursion is mathematical induction in action. In both, we have general and boundary conditions, with the general condition breaking the problem into smaller and smaller pieces. The initial or boundary condition terminates the recursion.
- The simplest and most common form of mathematical induction infers that a statement involving a natural number
n(that is, an integern ≥ 0) holds for all values ofn. The proof consists of two steps:- The initial or base case: prove that the statement holds for a fixed natural number (usually 0 or 1).
- The induction/inductive step: assume that the statement holds for some arbitrary natural number
n = k, and prove that the statement holds forn = k + 1.
- The hypothesis in the inductive step, that the statement holds for
n = k, is called the induction/inductive hypothesis. You're doing a thought experiment of what would happen if it was true forn = k. It might be clearer to use the phrase "suppose true whenn = k" rather than "assume true whenn = k" to emphasise this. - To prove the inductive step, one assumes the induction hypothesis for
n = kand then uses this assumption to prove that the statement holds forn = k + 1. We try to manipulate the statement forn = k + 1so that it involves the case forn = k(which we assumed to be true).
Inductive proof for Insertion sort
- The basis case consists of a single element, and by definition a one-element array is completely sorted.
- We assume that the first
n - 1elements of arrayAare completely sorted aftern - 1iterations of insertion sort. - To insert one last element
xtoA, we find where it goes, namely the unique spot between the biggest element less than or equal toxand the smallest element greater thanx. This is done by moving all the greater elements back by one position, creating room forxin the desired location. ■
Modeling the Problem
- Modeling is the art of formulating your application in terms of precisely described, well-understood problems.
- Proper modeling is the key to applying algorithmic design techniques to real-world problems — it can eliminate the need to design an algorithm, by relating your application to what has been done before.
- Real-world applications involve real-world objects — like a system to route traffic in a network or find the best way to schedule classrooms in a university.
- Most algorithms, however, are designed to work on rigorously defined abstract structures such as permutations, graphs, and sets.
- To exploit the algorithms literature, you must learn to describe your problem abstractly, in terms of procedures on such fundamental structures.
- The act of modeling reduces your application to one of a small number of existing problems and structures. Such a process is inherently constraining, and certain details might not fit easily into the given target problem.
Proof by Contradiction
- The basic scheme of a contradiction argument is as follows:
- Assume that the hypothesis (the statement you want to prove) is false.
- Develop some logical consequences of this assumption.
- Show that one consequence is demonstrably false, thereby showing that the assumption is incorrect and the hypothesis is true.
- The classic contradiction argument is Euclid's proof that there are an infinite number of prime numbers:
- The negation of the claim would be that there are only a finite number of primes, say
m, which can be listed asp₁,..., pₘ. So let's assume this is the case and work with it. - Prime numbers have particular properties with respect to division. Suppose we construct the integer formed as the product of "all" of the listed primes: [ N = \prod{i = 1}^{m} p{i} ]
- This integer
Nhas the property that it is divisible by each and every one of the known primes, because of how it was built. - But consider the integer
N + 1. It can't be divisible byp₁ = 2, becauseNis. - The same is true for
p₂ = 3and every other listed prime. Since a +1 can’t be evenly split by any of the prime numbers because they are bigger. - Since
N + 1doesn't have any non-trivial factor, this means it must be prime. - But you asserted that there are exactly
mprime numbers, none of which areN + 1, becauseN + 1 > m. - This assertion is false, so there cannot be a bounded number of primes.
- The negation of the claim would be that there are only a finite number of primes, say
- For a contradiction argument to be convincing, the final consequence must be clearly, ridiculously false.
Estimation
- Principled guessing is called estimation.
- Estimation problems are best solved through some kind of logical reasoning process, typically a mix of principled calculations and analogies.
- Principled calculations give the answer as a function of quantities that either you already know, can look up on Google, or feel confident enough to guess.
- Analogies reference your past experiences, recalling those that seem similar to some aspect of the problem at hand.
Exercises
Finding counter examples
Show that
a + bcan be less thanmin(a, b).When:
a and b < 0(i.e: negative)
a <= b
Then:
min(a, b) = a
a + b < a
Example:
min(-6, -5) = -6
-6 + -5 = -6 -5 = -11
-11 < -6Show that
a × bcan be less thanmin(a, b).When:
a < 0(i.e: negative)
b > 0(i.e: positive)
Then:
min(a, b) = a
a * b < a
Example:
min(-3, 4) = -3
-3 * 4 = -12
-12 < -3Design/draw a road network with two points a and b such that the fastest route between a and b is not the shortest route.
1a──────c──────b2│ │3│ │4└────d────────┘56Route `acb` have a toll gate, is in development and have a speed limit.7Route `adb` is longer, but has none of these impediment.89Route `adb` will be faster than the shorter `acb` route.Design/draw a road network with two points a and b such that the shortest route between a and b is not the route with the fewest turns.
1a────┐ ┌────b2│ └─c─┘ │3│ │4└──────d──────┘56Route `acb` is the shortest but has 4 turns.7Route `adb` is the longest and has only 2 turns.
Induction
- Prove that for n ≥ 0, by induction.
Chapter 2: Algorithm Analysis
The analysis of algorithms is the process of finding the computational complexity of algorithms.

For an ordered list of size ( in the example above), binary search takes at most check steps ( steps in the example above); while linear search takes at most check steps ( steps in the example above).
🏋️♀️ Computational complexity
The computational complexity or simply complexity of an algorithm is the amount of resources required to run it.
Common types of resources include:
- ⏳ Time — Time complexity is the computational complexity that describes the amount of computer time it takes to run an algorithm. When "complexity" is used without qualification, this generally means time complexity.
- 🫙 Memory — Space complexity is the computational complexity that describes the amount of memory it takes to run an algorithm.
- 🎙️ Communication — The necessary amount of communication between executing parties in a distributed algorithm.
The computational complexity of an algorithm can be measured only when given a model of computation.
💻 The RAM model of computation
The most commonly used model of computation is the Random Access Machine (RAM) which is a hypothetical computation model where:
- Each simple operation (like
+,*,-,=,if,call, etc) takes exactly unit-time (i.e. 1 step). - Each complex operation (like loops and subroutines) is the composition of simple operations. The time it takes to run through a loop or execute a subprogram depends upon the number of loop iterations or the specific nature of the subprogram.
- Each memory access takes exactly unit-time (i.e. 1 step), regardless of data location (cache or disk). There is also unlimited memory.
The RAM is a simple model of how computers perform. It allows the analysis of algorithms in a machine-independent way by assuming that simple operations take a constant amount of time on a given computer and change only by a constant factor when run on a different computer.
It doesn’t capture the full complexity of real computers (e.g. multiplying two numbers takes more time than adding two numbers on most processors). However, the RAM is still an excellent model for understanding how an algorithm will perform on a real computer.
A model is a simplification or approximation of reality and hence will not reflect all of reality. […] "all models are wrong, but some are useful." — Model Selection and Multimodel Inference
🏭 Computational complexity functions
Under the RAM model, we measure the computational complexity by counting the number of simple operations (also called steps) an algorithm takes on a given problem instance.
As the amount of resources required to run an algorithm generally varies with the size of the input, the complexity is typically expressed as a function , where is the size of the input and is the computational complexity.
Aside: We can also use any other characteristic of the input influencing the computational complexity.
However, the complexity of an algorithm may vary dramatically for different inputs of the same size. Therefore, three complexity functions are commonly used:
- 🔵 Worst-case complexity: is the maximum of the complexity over all inputs of size .
- It expresses the resources used by an algorithm at most.
- e.g. the worst-case time complexity for a simple linear search on a list is and occurs when the desired element is the last element of the list or is not in the list.
- Worst-case analysis gives a safe analysis (the worst case is never underestimated), but one which can be overly pessimistic, since there may be no (realistic) input that would take this many steps.
- Generally, when "complexity" is used without being further specified, this is the worst-case computational complexity that is considered.
- 🟢 Average-case complexity: is the average of the complexity over all inputs of size .
- It expresses the resources used by an algorithm on average.
- Average-case analysis requires a notion of an "average" input to an algorithm, which leads to the problem of devising a probability distribution over inputs.
- e.g. the average-case time complexity for a simple linear search on a list is assuming the value searched for is in the list and each list element is equally likely to be the value searched for.
- Con: Determining what typical input means is difficult and average case analysis tends to be more difficult.
- 🔴 Best-case complexity: is the minimum of the complexity over all inputs of size .
- It expresses the resources used by an algorithm at least.
- e.g. the best case time complexity for a simple linear search on a list is and occurs when the desired element is the first element of the list.
- Con: It's unlikely to happen in practice.
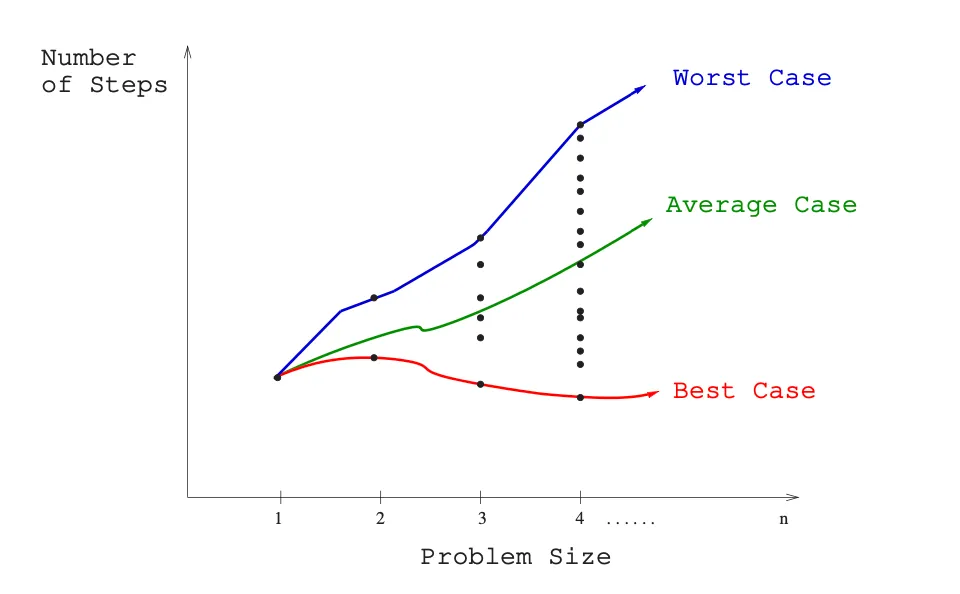
📈 Big oh notation
There are three problems with the complexity functions above:
- The exact computational complexity functions for any algorithm are liable to be complicated because they tend to have lots of up-and-down bumps.
- In addition, these exact values provide little practical application, as any change of computer or model of computation would change the complexity somewhat.
- Moreover, the resource use is not critical for small values of .
Complexity theory seeks to quantify the intrinsic time requirements of algorithms (independent of any external factors), that is, the basic time constraints an algorithm would place on any computer .
For these reasons, one generally focuses on the behavior of the complexity for large , that is on its asymptotic behavior when tends to infinity. Therefore, the complexity is generally expressed by using big O notation.
Big O notation is a mathematical notation that describes the limiting behavior of a function when the argument tends towards infinity. The formal definition of the big O notations are:
1. Big O (Upper bound)
Notation:
Meaning: There exists some constant such that for large enough (i.e. for all , for some constant ).
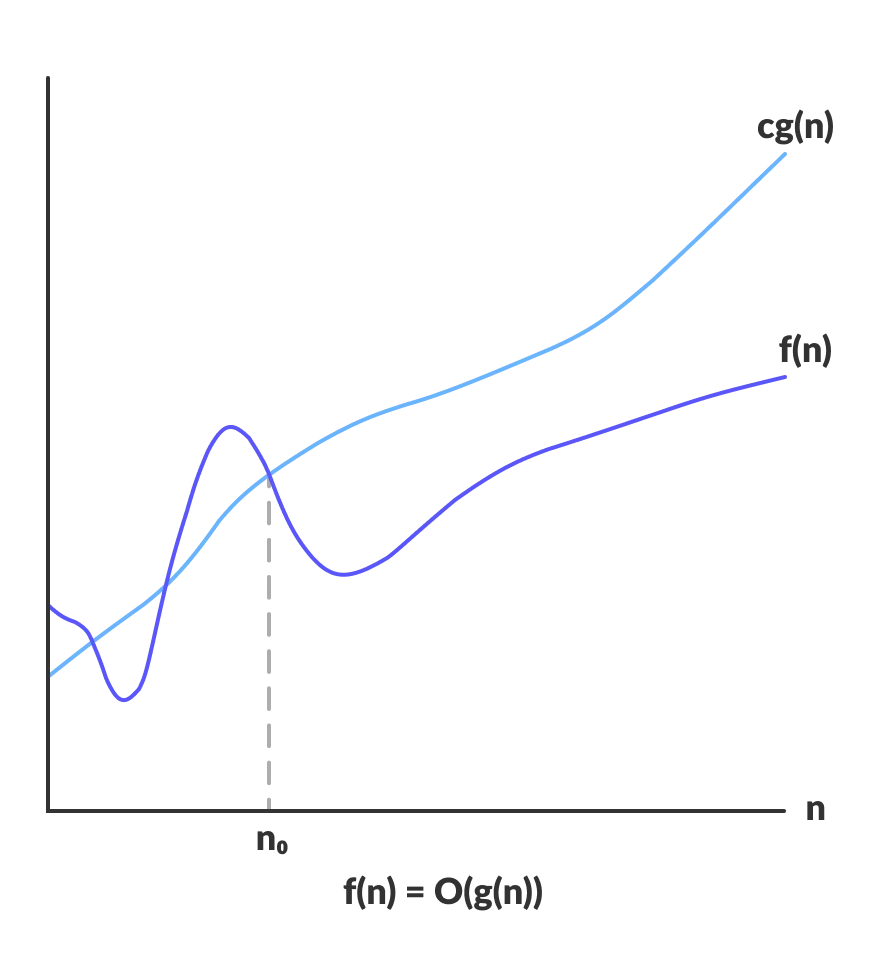
2. Big Omega (Lower bound)
Notation:
Meaning: Means there exists some constant such that for large enough (i.e. for all , for some constant ).
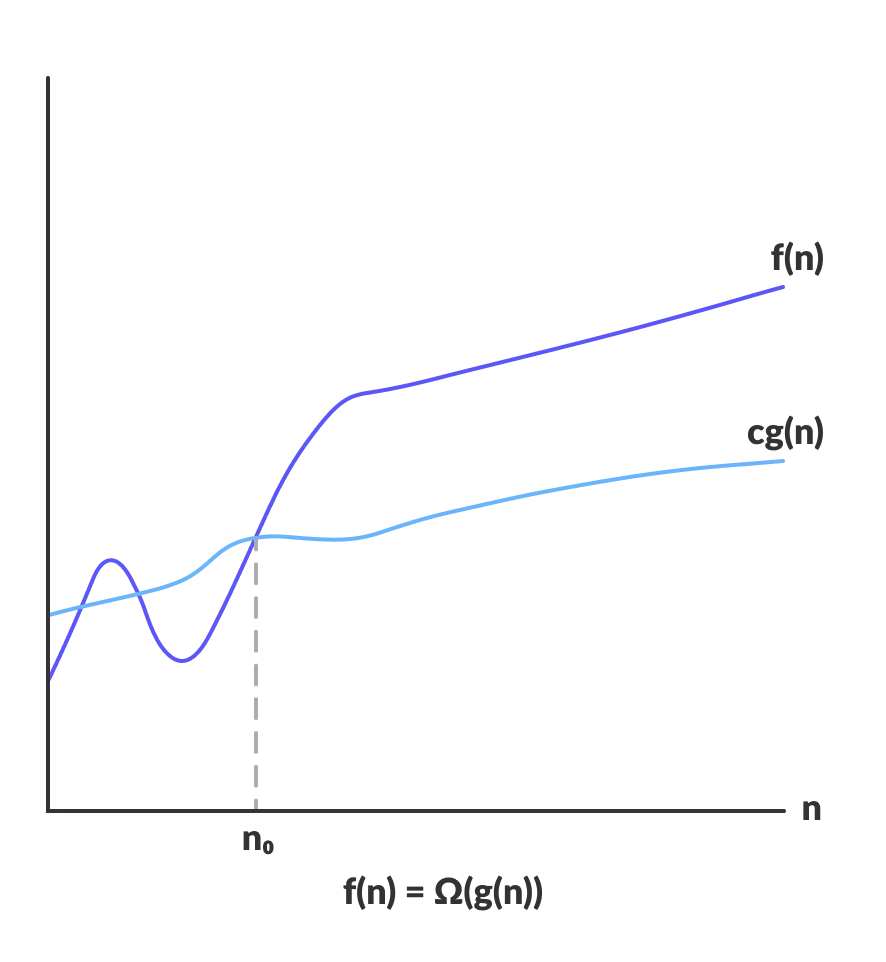
3. Big Theta (Tight bound [upper & lower bound])
Notation:
Meaning: Means there exists some constants and such that and for large enough (i.e. for all , for some constant ).
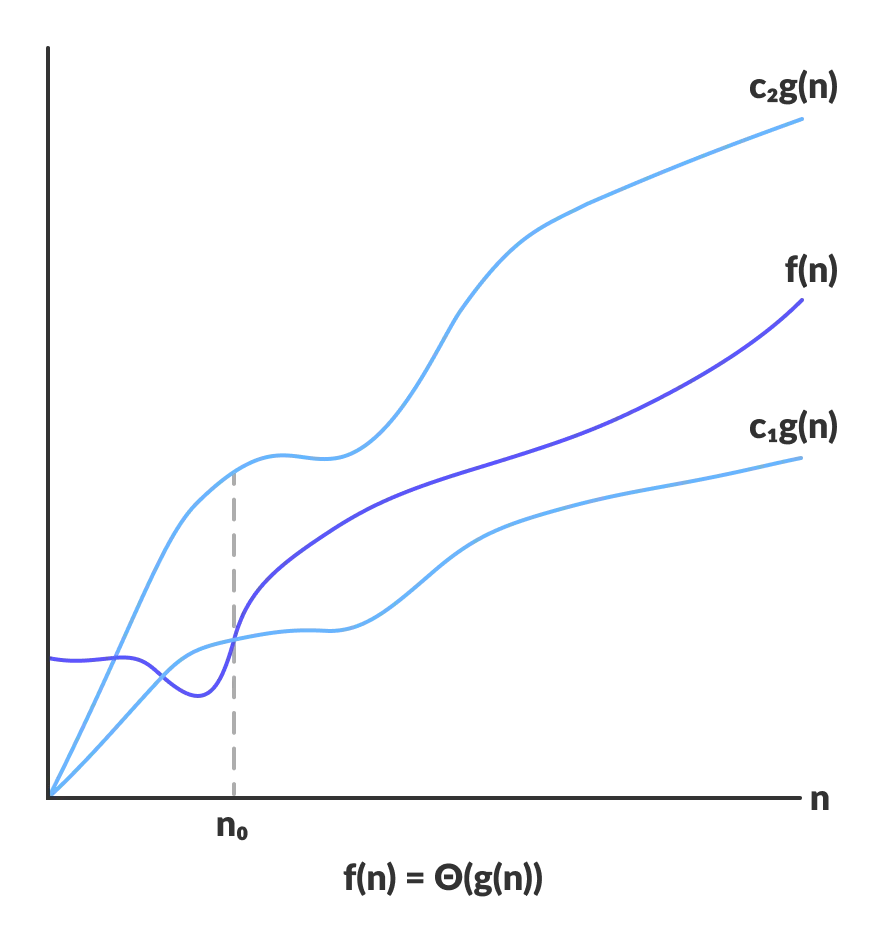
🙅♂️ Misconception: Conflating Big-O with complexity functions
The best/average/worst-case computational complexity is a function of the size of the input for a certain algorithm.
The , , and notations are used to describe the relationship between two functions.
Hence, each best/average/worst case computational complexity function has its corresponding , , and notation.
Conflating the big O notations with the computational complexity functions likely stems from the fact that in everyday use, “the big O of the worst-case computational complexity function” is used interchangeably with just “big O”, “time complexity”, “complexity”, etc.
🙈 Abuse of notation
There are two accepted abuses of notation in the computer science industry:
Abuse of the equal sign: Technically, the appropriate notation is , because the equal sign does not imply symmetry.
Abuse of the Big O notation: The big O notation is often used to describe an asymptotic tight bound where using big Theta notation would be more factually appropriate. Big O notation provides an upper bound, but it doesn't necessarily provide a tight upper bound. For example, is , but it is also , , etc. For contrast, the equation is only .
Common Big O functions
The function appearing within the is typically chosen to be as simple as possible, omitting constant factors and lower-order terms.
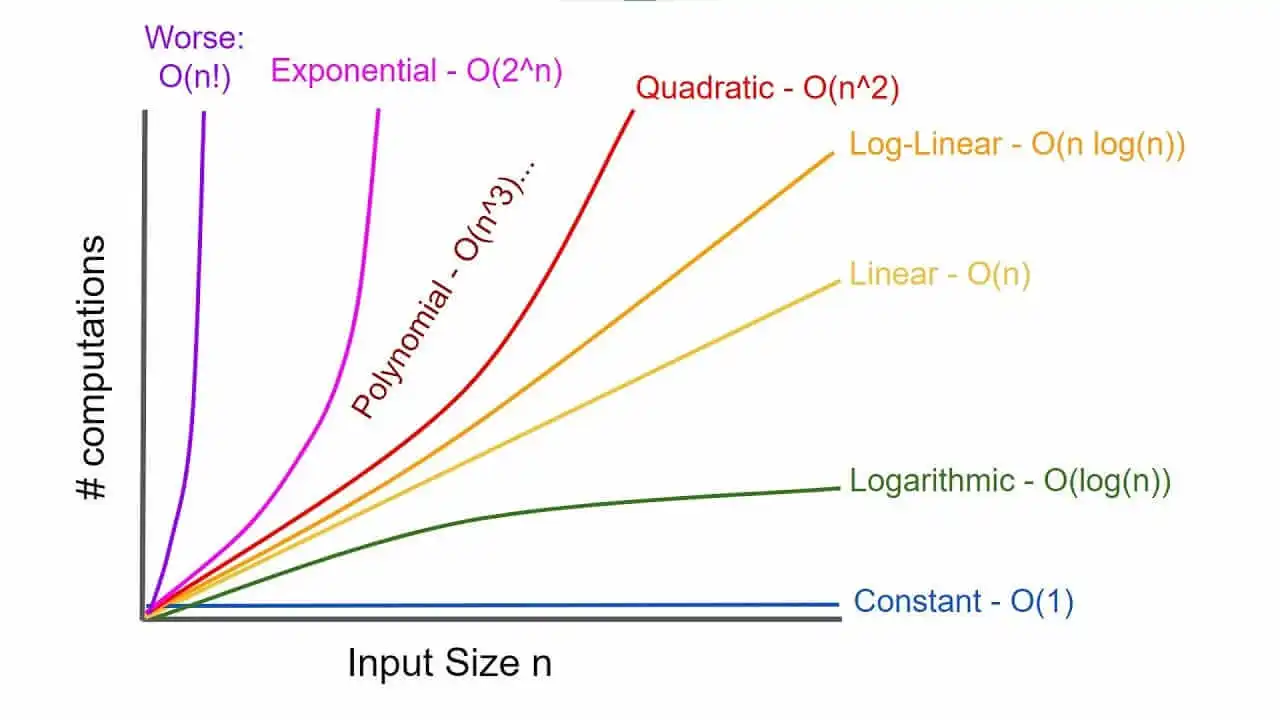
Constant functions:
- In the big picture, there is no dependence on the parameter .
- Such functions might measure the cost of adding two numbers or the growth realized by functions such as .
Logarithmic functions:
- Logarithmic time complexity shows up in algorithms such as binary search
- Such functions grow quite slowly as gets big.
Linear functions:
- Such functions measure the cost of looking at each item once (or twice, or ten times) in an -element array, say to identify the biggest item, the smallest item, or compute the average value.
Superlinear functions:
- This important class of functions arises in such algorithms as Quicksort and Mergesort.
Quadratic functions:
- Such functions measure the cost of looking at most or all pairs of items in an -element universe. This arises in algorithms such as insertion sort and selection sort.
Cubic functions:
- Such functions enumerate through all triples of items in an -element universe.
Exponential functions:
- for a given constant
- Functions like arise when enumerating all subsets of items.
Factorial functions:
- Functions like arise when generating all permutations or orderings of items.
Arithmetic operations with Big O notation
Addition:
- If is and is , then is .
- This is because the dominant function among and will dictate the overall growth rate.
Multiplication by a constant:
- If is , then is for any constant .
- This is because multiplying a function by a constant simply scales the function but does not change its growth rate.
Multiplication by non-constant:
- If is and is , then is .
- TODO: This is because the product of the dominant terms will determine the overall growth rate.
Transitivity:
- If is and is , then is .
- This property allows for chaining comparisons of functions.
Reasoning about an algorithm's efficiency
1. Selection sort
1// Selection sort repeatedly identifies the smallest remaining unsorted element2// and puts it at the end of the sorted portion of the array.3void selectionSort(int arr[], int n) {4 int i, j, minimum_element_index;56 // One by one move the boundary of the unsorted subarray7 for (i = 0; i < n; i++) {89 // Find the minimum element in the unsorted array10 minimum_element_index = i; // Assume the current element is the minimum11 12 for (j = i + 1; j < n; j++) {13 // If we find a smaller element, update the minimum_element_index14 if (arr[j] < arr[minimum_element_index]) {15 minimum_element_index = j;16 }17 }1819 // Swap the found minimum element with the first element20 swap(&arr[minimum_element_index], &arr[i]);21 }22}Analysis of the selection sort algorithm:
- The outer loop goes around times.
- The nested inner loop goes around times, where is the index of the outer loop.
- The exact number of times the
ifstatement is executed is:- To calculate the inner summation, we multiply the number of terms by .
- The number of terms in a summation can be calculated by subtracting the lower limit from the upper limit of the summation and then adding 1.
- This gives which equals . Obviously, multiplying that by gives the same result.
- Hence, the original equation simplifies to:
- What the sum is doing is adding up the non-negative integers in decreasing order starting from :
- The formula for the sum of the first non-negative integers (derived from the sum of an arithmetic series) is given by:
- Hence, we can simply the summation to:
- Therefore the time complexity of selection sort is:
- , , , etc.
Logarithms and their applications
A logarithm is an inverse exponential function:
Exponential functions grow at a fast rate while logarithmic functions grow at a slow rate. Logarithms arise in any process where things are repeatedly halved. e.g.
Logarithms and binary search:
- Binary search is an example of an algorithm.
- The size of the list is halved with each iteration of the algorithm.
- Thus, only comparisons suffice to find an element in an array with 1 million elements.

Logarithms and trees:
- A binary tree of height can have up to leaf nodes, while one of height can have up to leaves. The number of leaves doubles each time we increase the height by .
- To generalize to trees that have children, a tree of height can have up to leaf nodes, while one of height can have up to leaves. The number of leaves multiplies by each time we increase the height by .
- To account for leaves, , which implies that

Logarithms and bits:
- There are bit patterns of length (i.e. and ), of length (i.e. , , , ), and of length .
- The number of bit patterns doubles with each increase in the number of bits.
- Let represent number of bits and represent number of bit patterns. Then or .


Product property of logarithms
A direct consequence of the product property is the power property:
Since is a constant, this implies raising the logarithm’s argument to a power doesn't affect the growth rate:
Change of base property of logarithms
Changing the base of to base-c simply involves multiplying by :
Since and are constants, this property implies that the base of a logarithm has no impact on the growth rate:
Aside: In practice, an asymptotically inefficient algorithm may be more efficient for small input sizes. This is particularly used in hybrid algorithms, like Timsort, which use an asymptotically efficient algorithm (here merge sort, with time complexity ), but switch to an asymptotically inefficient algorithm (here insertion sort, with time complexity ) for small data, as the simpler algorithm is faster on small data.
Chapter 3: Data structures
- A data type (or simply type) is a collection of data values, usually specified by:
- A set of possible values,
- A set of allowed operations on these values, and/or
- A representation of these values as machine types.
- An abstract data type (ADT) is a data type that does not specify the concrete representation of the data. They are defined by their behavior (semantics) from the point of view of a user of the data, specifically in terms of:
- Possible values, and
- Possible operations on data of this type.
- The generic definition of data structure is anything that can hold your data in a structured way. ADT contrasts with data structures, which are concrete representations of data, and are the point of view of an implementer.
- The distinction between ADTs and data structures lies in the POV / level of abstraction. Some important points:
- User’s POV: An
intin a programming language sense is a fixed-width data structure. An integer in a mathematical sense is an ADT. For most purposes the user can work with the abstraction rather than the concrete choice of representation, and can simply use the data as if the type were truly abstract. - Name overloading: An array is an ADT when viewed as a collection of items that can be accessed by an index. An array is a data structure when viewed as a collection of fixed sized items stored as contiguous blocks in memory.
- ADT implementations: There are multiple implementations of an ADT. E.g: A list can be implemented as an array or a linked-list.
- User’s POV: An
- Data structures can be classified into:
- Contiguous data structures: composed of single slabs of memory. E.g. arrays, matrices, heaps, hash tables, etc.
- Linked data structures: composed of distinct chunks of memory bound together by pointers. E.g. linked-list, trees, graph adjacency lists, etc.
Arrays
- Arrays are data structures of fixed-size elements stored contiguously such that each element can be efficiently located by its index.
- Advantages of arrays:
- Constant-time access given the index: because the index of each element maps directly to a particular memory address.
- Space efficiency: because no space is wasted with links, end-of-element information, or other per element metadata.
- Memory locality: because the physical continuity between successive data access helps exploit the high-speed cache memory on modern computer architecture.
- The primary disadvantage of arrays is that the number of elements (i.e. the array size) is fixed. The capacity needs to be specified at allocation.
- Dynamic arrays overcome the fixed-size limitation of static arrays.
- It does so by internally resizing when its capacity is exceeded:
- Allocates a new bigger contiguous array.
- Copy the content of the old array to the new array.

- To avoid incurring the cost of resizing many times, dynamic arrays resize by a large amount, such as doubling in size.
- Expanding the array by any constant proportion ensures that inserting elements takes time overall, meaning that each insertion takes amortized time. As elements are added, the capacities form a geometric progression.
- The key idea of amortized analysis is to consider the worst-case cost of a sequence of operations on a data structure, rather than the worst-case individual cost of any particular operation.
- The aggregate method is one of the methods for performing amortized analysis. In this method, the total cost of performing a sequence of operations on the data structure is divided by the number of operations , yielding an average cost per operation, which is defined as the amortized cost.
- The aggregate method of amortized analysis applied to dynamic arrays with doubling:

defines the time it takes to perform the -th
addition.The first case of :
- Defines the time taken when the array’s capacity is exceeded and has to doubled.
- is a non-negative integer.
- Because the array's capacity is doubled, this case happens when: , , ..., .
- The time taken is because:
- elements has to be copied to the new array and
- The -th element has to be
addedinto the new array. This represents the .
The second case of :
- Defines the time taken when the array capacity is not exceeded.
- This is constant time because only a single
additionis performed.
e.g. Given a dynamic array initialized with a capacity of :
i 1 2 3 4 5 6 7 8 9 10 Capacity e.g. Given :
We see that in both cases of the function, there is a . So summation from to results in:
The second operand represents the total cost of the copy operation that occurs on each resizing. For
addition, this happens times. e.g.n 1 2 3 4 5 6 7 8 9 10 The second operand is the partial sum of a geometric series, which has the formula:
Applying the formula to the second operand:
is the number to which must be raised to obtain . Raising that number then to results in . Hence, the last expression can be simplified to:
The summation can be re-expressed again as:
The is inconsequencial in the time analysis, hence the summation can be simplified into:
Interpretation: A sequence of
addoperations costs at most , hence eachaddin the sequence costs at most (constant time) on average, which is the amortized cost according to the aggregate method.
Conclusion: This proves that the amortized cost of insertion to a dynamic array with doubling is .
- The key idea behind amortized analysis is that the cost of a particular operation can be partially paid for by the cost of other operations that are performed later. It avoids the limitations of worst-case analysis, which can overestimate the performance of a data structure if the worst-case scenario is unlikely to occur frequently.
Pointers and linked structures

Pointers represent the address of a location in memory. Pointers are the connections that hold the nodes (i.e. elements) of linked data structures together.
In C:
*pdenotes the item that is pointed to by pointerp&pdenotes the address of (i.e. pointer to) a particular variablep.- A special
NULLpointer value is used to denote unassigned pointers.
All linked data structures share these properties:
- Each node contains one or more data field.
- Each node contains a pointer field to at least one other node.
- Finally, we need a pointer to the head of the data structure, so we know where to access it.
Example linked-list displaying these properties:
1typedef struct list {2 data_type data; /* Data field */3 struct list *next; /* Pointer field */4} list;The linked-list is the simplest linked structure.
Singly linked-list has a pointer to only the successor whereas a doubly linked-list has a pointer to both the predecessor and successor.
Searching for data
xin a linked-list recursively:1list *search_list(list *my_list, data_type x) {2 if (my_list == NULL) {3 return(NULL);4 }56 // If `x` is in the list, it's either the first element or located in the rest of the list.7 if (my_list->data == x) {8 return(my_list);9 } else {10 return(search_list(my_list.next, x));11 }12}Inserting into a singly linked-list at the head:
1list *insert_list(list **my_list, data_type x) {2 list *p; /* temporary pointer */3 p = malloc(sizeof(list));4 p->data = x;5 p->next = *my_list;6 // `**my_list` denotes that `my_list` is a pointer to a pointer to a list node.7 // This line copies `p` to the place pointed to by `my_list`,8 // which is the external variable maintaining access to the head of the list.9 *my_list = p;10}Deletion from a list:
1// Used to find the predecessor of the item to be deleted.2list *item_ahead(list *my_list, list *x) {3 if ((my_list == NULL) || (my_list->next == NULL) {4 return(NULL);5 }67 if ((my_list->next) == x) {8 return(my_list);9 } else {10 return(item_ahead(my_list->next, x));11 }12}1314// This is called only if `x` exists in the list.15void *delete_list(list **my_list, list **x) {16 list *p; /* element pointer */17 list *pred; /* predecessor pointer */1819 p = *my_list;20 pred = item_ahead(*my_list, *x);2122 // Given that we assume `x` exists in the list,23 // `pred` is only null when the first element is the target.24 if (pred == NULL) { /* splice out of list */25 // Special case: resets the pointer to the head of the list26 // when the first element is deleted.27 *my_list = p->next;28 } else {29 pred->next = (*x)->next30 }3132 free(*x) /* free memory used by node */33}The advantages of linked structures over static arrays include:
- Overflow on linked structures never occurs unless the memory is actually full.
- Insertion and deletion are simpler than for static arrays. With static arrays, insertions and deletions into the middle requires manually shifting elements.
- With large records, moving pointers is easier and faster than moving the items themselves.
Both arrays and lists can be thought of as recursive objects:
- Lists — Chopping the first element off a linked-list leaves a smaller linked-list.
- Arrays — Splitting the first elements off of an element array gives two smaller arrays, of size and , respectively.
- This insight leads to simpler list processing, and efficient divide-and-conquer algorithms like quick-sort and binary search.
An array is only recursive conceptually: Every array "contains" a sub-array. However, an array isn't recursive in code: A structure is recursive if while navigating through it, you come across "smaller" versions of the whole structure. While navigating through an array, you only come across the elements that the array holds, not smaller arrays.
Stacks
- Stacks are an ADT that supports retrieval by last-in, first-out (LIFO).
- Primary operations are:
push(x)— Inserts itemxat the top of the stack.pop()— Return and remove the top item of the stack.
Queues
#/media/File:Data_Queue.svg)
- Queues are an ADT that supports retrieval by first-in, first-out (FIFO).
- Primary operations are:
enqueue(x)— Inserts itemxat the back of the queue.dequeue()— Return and remove the front item from the queue.
- Stacks and queues can be effectively implemented using arrays or linked-list.
Dictionaries
- A dictionary is an ADT that stores a collection of
(key, value) pairs, such that each possiblekeyappears at most once in the collection. - The primary operations of a dictionary are:
put(key, value)remove(key)get(key)
- These are two simple but less common implementations of a dictionary:
- An association list is a linked list in which each node comprises a key and a value:
- The time complexity of get and remove is .
- The time complexity of put is — if the list is unsorted.
- Direct addressing into an array:
- is the universe of numbers.
- is a set of potential keys and .
- can be kept under index in a -element array.
- The time complexity of put, get and remove is .
- The space complexity is . Hence, this structure is impractical when ; where is the number of values actually inserted.
- An association list is a linked list in which each node comprises a key and a value:
- These are the two common data structures used to implement a dictionary:
- Hash tables.
- Self-balancing binary search tree.
- Binary search tree based maps are in-order and hence can satisfy range queries (i.e. find all values between two bounds) whereas a hash-map can only efficiently find exact values.
Binary search tree (BST)
- A binary tree is a tree data structure in which each node has at most two children, referred to as the left child and the right child.
- A binary tree can be viewed as a linked-list with two pointers per node.
- A rooted tree is a tree in which one node has been designated the root.
- A rooted binary tree is recursively defined as either being:
- Empty or
- Consisting of a node called the root, together with two rooted binary trees called the left and right subtrees.
- A binary search tree is a rooted binary tree data structure such that for any node , all nodes in the left subtree of have while all nodes in the right subtree of have .
- Binary search trees’ height range from (when balanced) to (when degenerate).
- The time complexity of operations on the binary search tree is linear with respect to the height of the tree .
- Hence, in a balanced binary search tree, the nodes are laid out so that each comparison skips about half of the remaining tree, the lookup performance is proportional to that of the binary logarithm .
- An implementation of a binary tree:1typedef struct tree {2 data_type data; /* Data field */3 struct tree *parent; /* Pointer to parent */4 struct tree *left; /* Pointer to left chid */5 struct tree *right; /* Pointer to right child */6} tree;
- Searching in a binary search tree:
Priority queue
- A priority queue is an ADT similar to a regular queue or stack ADT. Each element in a priority queue has an associated
priority. - Depending on the implementation, a priority queue can serve minimum priority elements first or maximum priority elements first. You can convert one implementation into the other by negating the priority on each element addition.
- Priority queues are often implemented using heaps.
- A priority queue can also be inefficiently implemented as an unsorted list or a sorted list.
- A priority queue can be used for sorting: insert all the elements to be sorted into a priority queue, and sequentially remove them.
- The primary operations of a priority queue are:
add()— an element with a given priority,delete(x)— an element,pull()— Get the the highest priority element and remove it, andpeek()— Get the the highest priority element without removing it.
- Stacks and queues can be implemented as particular kinds of priority queues, with the priority determined by the order in which the elements are inserted.
Hash tables

Hash tables are a data structure that efficiently implements a dictionary. They exploit the fact that looking an element up in an array takes constant time once you have its index.
The basic idea is to pick a hash function that maps every possible key to a small integer . Then we store and its value in an array at index ; the array itself is essentially the hash table.
A hash function maps the universe of keys to array indices within the hash table.
Properties of a good hash function:
- Efficient — Computing should require a constant number of steps per bit of .
- Uniform — should ideally map elements randomly and uniformly over the entire range of integers.
A hash function for an arbitrary key (like a string) is typically defined as:
This is the polynomial function that Java uses to convert strings to integers:
Which translates into the following code:
1int hashcode = 0;2for (int i = 0; i < s.length(); i++) {3 hashcode = (hashcode * 31) + s.charAt(i);4}A collision occurs when:
Collisions can be minimized but cannot be eliminated (see Pigeon hole principle). It’s impossible to eliminate collisions without knowing the ahead of time.
The two common methods for collision resolution are separate chaining and open addressing.
In separate chaining, the values of the hash-table’s array is a linked-list.
Inserting adds the key and its value to the head of the linked-list at index in time. Keys that collided hence form a chain.
Searching involves going to index and iterating through the linked-list until a key equality check passes.

In open addressing, every key and its value is stored in the hash-table’s array itself, and the resolution is performed through
probing.- Inserting goes to index. If it is occupied, it proceeds on some probe sequence until an unoccupied index is found.
- Searching is done in the same sequence, until either the key is found, or an unoccupied array index is found, which indicates an unsuccessful search.
- Linear probing is often used — it simply checks the next indices linearly: , . But there is quadratic probing and other probing sequences.

Search algorithms that use hashing consist of two separate parts: hashing and collision resolution.
Other uses of hashing (or a hash table):

1* Plagiarism detection using Rabin-Karp string matching algorithm2* English dictionary search3* Finding distinct elements4* Counting frequencies of itemsTime complexity in big O notation
Operation Average Worst case Search Insert Delete Space complexity is .
Excercises
A common problem for compilers and text editors is determining whether the parentheses in a string are balanced and properly nested. For example, the string
((())())()contains properly nested pairs of parentheses, while the strings)()(and())do not. Give an algorithm that returns true if a string contains properly nested and balanced parentheses, and false if otherwise. For full credit, identify the position of the first offending parenthesis if the string is not properly nested and balanced.Solution
1fun test() {2 System.out.println(areParentheseProperlyBalanced("((())())()"))3 System.out.println(areParentheseProperlyBalanced(")()("))4 System.out.println(areParentheseProperlyBalanced("())"))5 System.out.println(areParentheseProperlyBalanced(")))"))6 System.out.println(areParentheseProperlyBalanced("(("))7 }89/**10 * @return -1 if [string] is valid, else a positive integer11 * that provides the position of the offending index.12 */13fun areParentheseProperlyBalanced(string: String): Int {14 val stack = Stack<Pair<Char, Int>>()1516 string.forEachIndexed { index, char ->17 if (char == '(') {18 stack.push(char to index)19 } else if (char == ')') {20 if (stack.empty()) {21 return index22 }23 stack.pop()24 } else {25 throw IllegalArgumentException("Only parenthesis are supported")26 }27 }2829 return if (stack.empty()) -1 else stack.peek().second30 }Give an algorithm that takes a string consisting of opening and closing parentheses, say
)()(())()()))())))(, and finds the length of the longest balanced parentheses in , which is 12 in the example above. (Hint: The solution is not necessarily a contiguous run of parenthesis from )Solution
1fun test() {2 System.out.println(lengthOfLongestBalancedParentheses("((())())()"))3 System.out.println(lengthOfLongestBalancedParentheses(")()(())()()))())))("))4 System.out.println(lengthOfLongestBalancedParentheses(")()("))5 System.out.println(lengthOfLongestBalancedParentheses("())"))6 System.out.println(lengthOfLongestBalancedParentheses(")))"))7 System.out.println(lengthOfLongestBalancedParentheses("(("))8}910fun lengthOfLongestBalancedParentheses(string: String): Int {11 val stack = Stack<Char>()12 var numBalancedParenthesis = 01314 string.forEachIndexed { index, char ->15 if (char == '(') {16 stack.push(char)17 } else if (char == ')') {18 if (!stack.empty()) {19 stack.pop()20 numBalancedParenthesis++21 }22 }23 }2425 // Multiplied by 2 because each balanced pair has a length of 2.26 return numBalancedParenthesis * 227}Give an algorithm to reverse the direction of a given singly linked list. In other words, after the reversal all pointers should now point backwards. Your algorithm should take linear time.
Solution
1fun test() {2 val node1 = Node("Elvis", null)34 val node2 = Node("Chidera", null)5 node1.next = node267 val node3 = Node("Nnajiofor", null)8 node2.next = node3910 System.out.println(node1)11 System.out.println(reverse(node1))12}1314data class Node(15 val element: String,16 var next: Node?17)1819/**20 * Work through an example:21 * reverse(Node1 -> Node2 -> Node3)22 *23 * Node1 level:24 * val last = reverse(Node2 -> Node3) 🛑25 *26 * Node2 level:27 * val last = reverse(Node3) 🛑28 *29 * Node3 level:30 * return Node331 *32 * Back to Node2 level:33 * val last = Node3 🟢34 * Node3.next = Node235 * Node2.next = null36 * return last37 *38 * Back to Node1 level:39 * val last = Node3 🟢40 * Node2.next = Node141 * Node1.next = null42 * return last43*/44fun reverse(node: Node): Node {45 // Base case46 if (node.next == null) return node4748 val last = reverse(node.next!!)49 node.next!!.next = node50 node.next = null51 return last52}Design a stack that supports
S.push(x),S.pop(), andS.findmin(), which returns the minimum element of . All operations should run in constant time.Solution
1fun test() {2 val stack = Stack()3 stack.push(50)4 stack.push(40)5 stack.push(30)6 stack.push(20)7 stack.push(10)89 System.out.println(stack.findMin())10 stack.pop()11 System.out.println(stack.findMin())12 stack.pop()13 System.out.println(stack.findMin())14 stack.pop()15 System.out.println(stack.findMin())16 stack.pop()17 System.out.println(stack.findMin())18 stack.pop()19}2021data class Element(22 val num: Int,23 internal val minNumSoFar: Int24)2526class Stack {2728 private val list = mutableListOf<Element>()2930 fun push(num: Int) {31 list += Element(32 num = num,33 minNumSoFar = Math.min(num, list.lastOrNull()?.minNumSoFar ?: num)34 )35 }3637 fun pop(): Int {38 return list.removeLast().num39 }4041 fun findMin(): Int {42 return list.last().minNumSoFar43 }44}We have seen how dynamic arrays enable arrays to grow while still achieving constant-time amortized performance. This problem concerns extending dynamic arrays to let them both grow and shrink on demand.
a. Consider an underflow strategy that cuts the array size in half whenever the array falls below half full. Give an example sequence of insertions and deletions where this strategy gives a bad amortized cost.
b. Then, give a better underflow strategy than that suggested above, one that achieves constant amortized cost per deletion.
Solution
a. A sequence of
insert,insert,delete,insert,delete,insertwill lead to a bad amortized cost because the array will be busy resizing for most of the operations.b. A better underflow strategy is to cut the array size in half whenever the array falls below . is arbitrary, but it gives the array good "slack" space. The goal is to select a number such that the array is not busy resizing for most of the operation. The smaller the cut-off ratio, the smaller the number of resizing but the more space the array uses.
Suppose you seek to maintain the contents of a refrigerator so as to minimize food spoilage. What data structure should you use, and how should you use it?
Solution
Use a priority queue. The expiry date is the priority of each element. Elements with the lowest expiry date are served first (
minElement).Work out the details of supporting constant-time deletion from a singly linked list as per the footnote from page 79, ideally to an actual implementation. Support the other operations as efficiently as possible.
Solution
1fun test() {2 val node3 = Node(3)3 val node2 = Node(2, node3)4 val node1 = Node(1, node2)56 println(node1)7 println(deleteInConstantTime(node1, node2))8 println(deleteInConstantTime(node1, node3))9 println(deleteInConstantTime(node1, node1))10}1112fun deleteInConstantTime(head: Node, search: Node): Node? {13 if (head == search) {14 // Handle head case15 return head.next16 }1718 var node: Node? = head19 var prevNode: Node? = null20 while (node != null) {21 if (node == search) {22 if (node.next == null) {23 // Handle tail case24 prevNode?.next = null25 } else {26 node.element = node.next!!.element27 node.next = node.next?.next28 }2930 break31 } else {32 prevNode = node33 node = node.next34 }35 }3637 return head38}3940data class Node(41 var element: Int,42 var next: Node? = null43)Tic-tac-toe is a game played on an board (typically ) where two players take consecutive turns placing “O” and “X” marks onto the board cells. The game is won if consecutive “O” or “X” marks are placed in a row, column, or diagonal. Create a data structure with space that accepts a sequence of moves, and reports in constant time whether the last move won the game.
Solution
1fun test() {2 var tickTacToe = TickTacToe(3)3 assertFalse(tickTacToe.playX(1, 1))4 assertFalse(tickTacToe.playO(1, 2))5 assertFalse(tickTacToe.playX(1, 3))67 tickTacToe = TickTacToe(3)8 assertFalse(tickTacToe.playO(2, 1))9 assertFalse(tickTacToe.playX(2, 2))10 assertFalse(tickTacToe.playO(2, 3))1112 tickTacToe = TickTacToe(3)13 assertFalse(tickTacToe.playX(3, 1))14 assertFalse(tickTacToe.playX(3, 2))15 assertTrue(tickTacToe.playX(3, 3))1617 tickTacToe = TickTacToe(3)18 assertFalse(tickTacToe.playX(1, 1))19 assertFalse(tickTacToe.playO(2, 1))20 assertFalse(tickTacToe.playX(3, 1))2122 tickTacToe = TickTacToe(3)23 assertFalse(tickTacToe.playO(1, 2))24 assertFalse(tickTacToe.playX(2, 2))25 assertFalse(tickTacToe.playO(3, 2))2627 tickTacToe = TickTacToe(3)28 assertFalse(tickTacToe.playX(1, 3))29 assertFalse(tickTacToe.playX(2, 3))30 assertTrue(tickTacToe.playX(3, 3))3132 tickTacToe = TickTacToe(3)33 assertFalse(tickTacToe.playO(1, 1))34 assertFalse(tickTacToe.playO(2, 2))35 assertTrue(tickTacToe.playO(3, 3))3637 tickTacToe = TickTacToe(3)38 assertFalse(tickTacToe.playO(1, 3))39 assertFalse(tickTacToe.playO(2, 2))40 assertTrue(tickTacToe.playO(3, 1))41}4243private fun assertTrue(value: Boolean) {44 require(value)45 println("Won!!!")46}4748private fun assertFalse(value: Boolean) {49 require(!value)50 println("Not won yet")51}5253class TickTacToe(private val n: Int) {5455 private val columns = Array(n) {56 Slot(n)57 }5859 private val rows = Array(n) {60 Slot(n)61 }6263 private val diagonal = Slot(n)6465 private val antiDiagonal = Slot(n)6667 fun playX(rowPosition: Int, columnPosition: Int): Boolean {68 return play('X', rowPosition, columnPosition)69 }7071 fun playO(rowPosition: Int, columnPosition: Int): Boolean {72 return play('O', rowPosition, columnPosition)73 }7475 private fun play(char: Char, rowPosition: Int, columnPosition: Int): Boolean {76 return rows[rowPosition.toIndex].play(char) ||77 columns[columnPosition.toIndex].play(char) ||78 (rowPosition == columnPosition && diagonal.play(char)) ||79 ((rowPosition + columnPosition) == (n + 1) && antiDiagonal.play(char))80 }8182 private val Int.toIndex get() = this - 18384 class Slot(private val n: Int) {8586 private var number = 08788 fun play(char: Char): Boolean {89 val increment = if (char == 'X') 1 else -190 val target = if (char == 'X') n else -n9192 number += increment93 return number == target94 }95 }96}Write a function which, given a sequence of digits 2–9 and a dictionary of words, reports all words described by this sequence when typed in on a standard telephone keypad. For the sequence 269 you should return any, box, boy, and cow, among other words.
Solution
1fun test() {2 println(words(arrayOf(2, 6, 9)))3 println(words(arrayOf(7, 6, 7, 7)))4}56fun words(inputDigits: Array<Int>): List<String> {7 val words = setOf(8 "pops",9 "any",10 "box",11 "boy",12 "cow",13 "dad",14 "mom",15 )16 val charToDigitMapping = mapOf(17 'a' to 2,18 'b' to 2,19 'c' to 2,20 'd' to 3,21 'e' to 3,22 'f' to 3,23 'g' to 4,24 'h' to 4,25 'i' to 4,26 'j' to 5,27 'k' to 5,28 'l' to 5,29 'm' to 6,30 'n' to 6,31 'o' to 6,32 'p' to 7,33 'q' to 7,34 'r' to 7,35 's' to 7,36 't' to 8,37 'u' to 8,38 'v' to 8,39 'w' to 9,40 'x' to 9,41 'y' to 9,42 'z' to 9,43 )4445 val matchingWords = mutableListOf<String>()46 words.forEach { word ->47 word.forEachIndexed { index, char ->48 val charDigit = charToDigitMapping[char] ?: return@forEach49 val inputDigitAtIndex = inputDigits.getOrNull(index) ?: return@forEach50 if (charDigit != inputDigitAtIndex) {51 return@forEach52 }53 }5455 matchingWords += word56 }5758 return matchingWords59}Two strings and are anagrams if the letters of can be rearranged to form . For example, silent/listen, and incest/insect are anagrams. Give an efficient algorithm to determine whether strings and are anagrams.
Solution
1fun test() {2 println(isAnagram("silent", "listen"))3 println(isAnagram("silence", "listen"))4 println(isAnagram("incest", "insect"))5 println(isAnagram("incest", "insects"))6}78fun isAnagram(s1: String, s2: String): Boolean {9 val map = mutableMapOf<Char, Int>()1011 s1.forEach { char ->12 map[char] = map.getOrPut(char) { 0 } + 113 }1415 s2.forEach { char ->16 if (map.containsKey(char)) {17 map[char] = map.getValue(char) - 118 } else {19 return false20 }21 }2223 map.values.forEach { number ->24 if (number != 0) {25 return false26 }27 }2829 return true30}Design a dictionary data structure in which
search,insertion, anddeletioncan all be processed in time in the worst case. You may assume the set elements are integers drawn from a finite set and initialization can take time.Solution
1fun test() {2 val dictionary = Dictionary(10)3 dictionary.insert(4)4 println(dictionary.search(4))5 dictionary.delete(4)6 println(dictionary.search(4))7}89class Dictionary(val capacity: Int) {1011 private val array = Array<Int?>(capacity) { null }1213 fun search(element: Int): Int? {14 return array[element.toIndex]15 }1617 fun delete(element: Int) {18 array[element.toIndex] = null19 }2021 fun insert(element: Int) {22 array[element.toIndex] = element23 }2425 private val Int.toIndex get() = this - 126}The maximum depth of a binary tree is the number of nodes on the path from the root down to the most distant leaf node. Give an algorithm to find the maximum depth of a binary tree with nodes.
Solution
1fun test() {2 val root = BNode(3 element = 5,4 left = BNode(5 element = 3,6 left = BNode(7 element = 2,8 left = BNode(9 element = 1,10 left = null,11 right = null12 ),13 right = null14 ),15 right = null16 ),17 right = BNode(18 element = 7,19 left = null,20 right = BNode(21 element = 8,22 left = null,23 right = null24 )25 )26 )2728 println(maxDepth(root))29}3031fun maxDepth(root: BNode?): Int {32 if (root == null) {33 return 034 }3536 val leftDepth = maxDepth(root.left)37 val rightDepth = maxDepth(root.right)3839 return max(leftDepth, rightDepth) + 140}Two elements of a binary search tree have been swapped by mistake. Give an algorithm to identify these two elements so they can be swapped back.
Solution
1fun test() {2 val root = BNode(3 element = 5,4 left = BNode(5 element = 3,6 left = BNode(7 element = 8, // Swapped8 left = null,9 right = null10 ),11 right = null12 ),13 right = BNode(14 element = 7,15 left = null,16 right = BNode(17 element = 2, // Swapped18 left = null,19 right = null20 )21 )22 )2324 println(root)25 val recoverer = SwappedNodeRecoverer()26 recoverer.recover(root)27 println(root)28}2930class SwappedNodeRecoverer {3132 private var prev: BNode? = null33 private var first: BNode? = null34 private var second: BNode? = null3536 fun recover(root: BNode?) {37 recoverInternal(root)3839 if (first != null) {40 val firstElement = first!!.element41 first!!.element = second!!.element42 second!!.element = firstElement43 }44 }4546 private fun recoverInternal(root: BNode?) {47 if (root == null) {48 return49 }5051 recoverInternal(root.left)5253 if (prev != null && root.element < prev!!.element) {54 if (first == null) {55 // This handles adjacent node case56 first = prev57 second = root58 } else {59 second = root60 }61 }6263 prev = root6465 recoverInternal(root.right)66 }67}6869data class BNode(70 var element: Int,71 var left: BNode? = null,72 var right: BNode? = null,73)Given two binary search trees, merge them into a doubly linked list in sorted order.
Solution
1fun test() {2 val s1 = BNode(3 element = 5,4 left = BNode(5 element = 3,6 left = null,7 right = null8 ),9 right = BNode(10 element = 7,11 left = null,12 right = null13 )14 )1516 val s2 = BNode(17 element = 10,18 left = BNode(19 element = 8,20 left = null,21 right = null22 ),23 right = BNode(24 element = 12,25 left = null,26 right = null27 )28 )2930 println(merge(s1, s2))31}3233fun merge(tree1: BNode, tree2: BNode): Node {34 val tree1Nodes = toList(tree1)35 val tree2Nodes = toList(tree2)3637 var i1 = 038 var i2 = 039 val list = Node(Integer.MIN_VALUE) // Sentinel40 var lastListNode = list41 val addListNode = { node: Node ->42 lastListNode.next = node43 lastListNode = node44 }4546 while (i1 < tree1Nodes.size || i2 < tree2Nodes.size) {47 val tree1Node = tree1Nodes.getOrNull(i1)48 val tree2Node = tree2Nodes.getOrNull(i2)4950 if (tree1Node == null && tree2Node != null) {51 addListNode(Node(tree2Node.element))52 i2++53 } else if (tree2Node == null && tree1Node != null) {54 addListNode(Node(tree1Node.element))55 i1++56 } else if (tree1Node!!.element < tree2Node!!.element) {57 addListNode(Node(tree1Node.element))58 i1++59 } else if(tree1Node.element > tree2Node.element) {60 addListNode(Node(tree2Node.element))61 i2++62 } else {63 addListNode(Node(tree1Node.element))64 i1++65 addListNode(Node(tree2Node.element))66 i2++67 }68 }6970 return list.next!!71}7273fun toList(tree: BNode?): MutableList<BNode> {74 if (tree == null) {75 return mutableListOf()76 }7778 return (toList(tree.left) + tree + toList(tree.right)).toMutableList()79}8081data class BNode(82 val element: Int,83 var left: BNode?,84 var right: BNode?,85)8687data class Node(88 val element: Int,89 var next: Node? = null90)Describe an -time algorithm that takes an -node binary search tree and constructs an equivalent height-balanced binary search tree. In a height-balanced binary search tree, the difference between the height of the left and right subtrees of every node is never more than 1.
Solution
1fun test() {2 val root = BNode(3 element = 5,4 left = BNode(5 element = 3,6 left = BNode(7 element = 2,8 left = BNode(9 element = 1,10 left = null,11 right = null12 ),13 right = null14 ),15 right = null16 ),17 right = BNode(18 element = 7,19 left = null,20 right = BNode(21 element = 8,22 left = null,23 right = null24 )25 )26 )2728 println("Unbalanced tree: $root")29 println("Balanced tree: " + toBalancedTree(root))30}3132fun toBalancedTree(root: BNode): BNode {33 val nodes = toList(root)34 return sortedListToBinaryTree(nodes)!!35}3637fun sortedListToBinaryTree(list: List<BNode>): BNode? {38 if (list.isEmpty()) {39 return null40 }4142 val mid = list.size / 243 val root = BNode(list[mid].element)44 root.left = sortedListToBinaryTree(list.slice(0 until mid))45 root.right = sortedListToBinaryTree(list.slice((mid + 1) until list.size))4647 return root48}4950fun toList(tree: BNode?): MutableList<BNode> {51 if (tree == null) {52 return mutableListOf()53 }5455 return (toList(tree.left) + tree + toList(tree.right)).toMutableList()56}5758data class BNode(59 val element: Int,60 var left: BNode? = null,61 var right: BNode? = null,62)Find the storage efficiency ratio (the ratio of data space over total space) for each of the following binary tree implementations on nodes:
- All nodes store data, two child pointers, and a parent pointer. The data field requires 4 bytes and each pointer requires 4 bytes.
- Only leaf nodes store data; internal nodes store two child pointers. The data field requires four bytes and each pointer requires two bytes.
Solution
Storage efficiency ratio = For option A: Space taken by a single node = (2 pointers 4 bytes) + (1 pointer 4 bytes) + (4 bytes) = 16 bytes Given nodes Storage efficiency ratio =
For option B: Space taken by a single internal node = 2 pointers * 2 bytes = 4 bytes Space taken by a single leaf node = 4 bytes In a full tree, given leaf nodes, there are internal nodes. Storage efficiency ratio = (As gets larger, the constant doesn't matter, hence why it was dropped)
Option B has a higher storage efficiency to option A.
Give an algorithm that determines whether a given -node binary tree is height-balanced (see Problem 3-15).
Solution
1fun test() {2 val root = BNode(3 element = 5,4 left = BNode(5 element = 3,6 left = BNode(7 element = 2,8 left = BNode(9 element = 1,10 left = null,11 right = null12 ),13 right = null14 ),15 right = null16 ),17 right = BNode(18 element = 7,19 left = null,20 right = BNode(21 element = 8,22 left = null,23 right = null24 )25 )26 )2728 println(isBalanced(root))29}3031fun isBalanced(root: BNode?): Pair<Boolean, Int> {32 if (root == null) {33 return true to 034 }3536 val (isLeftBalanced, leftHeight) = isBalanced(root.left)37 if (!isLeftBalanced) {38 return false to 039 }4041 val (isRightBalanced, rightHeight) = isBalanced(root.right)42 if (!isRightBalanced) {43 return false to 044 }4546 if (abs(leftHeight - rightHeight) > 1) {47 return false to 048 }4950 return true to (max(leftHeight, rightHeight) + 1)51}5253data class BNode(54 val element: Int,55 val left: BNode?,56 val right: BNode?,57)Describe how to modify any balanced tree data structure such that search, insert, delete, minimum, and maximum still take time each, but successor and predecessor now take time each. Which operations have to be modified to support this?
Solution
TODO
Suppose you have access to a balanced dictionary data structure that supports each of the operations search, insert, delete, minimum, maximum, successor, and predecessor in time. Explain how to modify the insert and delete operations so they still take but now minimum and maximum take time. (Hint: think in terms of using the abstract dictionary operations, instead of mucking about with pointers and the like.)
Solution
Use two variables to maintain the maximum and minimum element. On:
Insert(x): If , set as new minimum; If , set as new maximum.Delete(x): If , set ; If , set .
Design a data structure to support the following operations:
insert(x,T)– Insert item into the set .delete(k,T)– Delete the th smallest element from .member(x,T)– Return true iff .
All operations must take time on an -element set.
Solution
g
A concatenate operation takes two sets and , where every key in is smaller than any key in , and merges them. Give an algorithm to concatenate two binary search trees into one binary search tree. The worst-case running time should be , where is the maximal height of the two trees.
Solution
1fun test() {2 val s1 = BNode(3 element = 5,4 left = BNode(5 element = 3,6 left = null,7 right = null8 ),9 right = BNode(10 element = 7,11 left = null,12 right = null13 )14 )1516 val s2 = BNode(17 element = 10,18 left = BNode(19 element = 8,20 left = null,21 right = null22 ),23 right = BNode(24 element = 12,25 left = null,26 right = null27 )28 )2930 println(concat(s1, s2))31}3233fun concat(s1: BNode, s2: BNode): BNode {34 val s1RightMostNode = rightMostNode(s1)3536 s1RightMostNode.right = s23738 return s139}4041fun rightMostNode(node: BNode): BNode {42 if (node.right == null) {43 return node44 }4546 return rightMostNode(node.right!!)47}4849data class BNode(50 val element: Int,51 var left: BNode?,52 var right: BNode?,53)Design a data structure that supports the following two operations:
insert(x)– Insert item from the data stream to the data structure.median()– Return the median of all elements so far.
All operations must take time on an -element set.
Solution
1fun test() {2 val ds = DataStructure()34 ds.insert(5)5 ds.insert(2)6 ds.insert(3)78 println("Median: ${ds.median()}")910 ds.insert(4)11 println("Median: ${ds.median()}")12}1314class DataStructure {1516 /* The head of this queue is the least element with respect to the specified ordering. */17 private val minHeap = PriorityQueue<Int>() // Represents the upper half18 private val maxHeap = PriorityQueue<Int>() // Represents the lower half1920 fun insert(x: Int) {21 if (maxHeap.isEmpty() || x <= -maxHeap.peek()) {22 maxHeap.offer(-x)23 } else {24 minHeap.offer(x)25 }2627 // Balance the heaps to ensure the size difference is at most 128 if (maxHeap.size > minHeap.size + 1) {29 minHeap.offer(-maxHeap.poll())30 } else if (minHeap.size > maxHeap.size) {31 maxHeap.offer(-minHeap.poll())32 }33 }3435 fun median(): Double {36 return if (minHeap.size == maxHeap.size) {37 // If the number of elements is even, take the average of the middle two38 (minHeap.peek() + (-maxHeap.peek())) / 2.039 } else {40 -maxHeap.peek().toDouble()41 }42 }43}Assume we are given a standard dictionary (balanced binary search tree) defined on a set of strings, each of length at most . We seek to print out all strings beginning with a particular prefix . Show how to do this in time, where is the number of strings.
Solution
g
An array is called -unique if it does not contain a pair of duplicate elements within positions of each other, that is, there is no and such that and . Design a worst-case algorithm to test if is -unique.
Solution
g
In the bin-packing problem, we are given objects, each weighing at most 1 kilogram. Our goal is to find the smallest number of bins that will hold the objects, with each bin holding 1 kilogram at most.
- The best-fit heuristic for bin packing is as follows. Consider the objects in the order in which they are given. For each object, place it into the partially filled bin with the smallest amount of extra room after the object is inserted. If no such bin exists, start a new bin. Design an algorithm that implements the best-fit heuristic (taking as input the weights and outputting the number of bins used) in time.
- Repeat the above using the worst-fit heuristic, where we put the next object into the partially filled bin with the largest amount of extra room after the object is inserted.
Solution
g
Suppose that we are given a sequence of values and seek to quickly answer repeated queries of the form: given and , find the smallest value in . a. Design a data structure that uses space and answers queries in time. b. Design a data structure that uses space and answers queries in time. For partial credit, your data structure can use space and have query time.
Solution
1fun test() {2 val numbers1 = listOf(1, 3, 9, 2, 5)3 println(solutionA(numbers1, 2, 5))4 println(solutionA(numbers1, 1, 3))5 println(solutionB(numbers1, 2, 5))6 println(solutionB(numbers1, 1, 3))7}89fun solutionA(numbers: List<Int>, i: Int, j: Int): Int? {10 val list = Array<Array<Int?>>(numbers.size) { Array(numbers.size) { null } }1112 for (p in numbers.indices) {13 var minimumSoFar = Int.MAX_VALUE1415 for (q in (p+1) until numbers.size) {16 val qthNumber = numbers[q]17 if (qthNumber < minimumSoFar) {18 minimumSoFar = qthNumber19 }2021 list[p][q] = minimumSoFar22 }23 }2425 return list[i-1][j-1]26}2728fun solutionB(numbers: List<Int>, i: Int, j: Int): Int? {29 TODO()30}Suppose you are given an input set of integers, and a black box that if given any sequence of integers and an integer instantly and correctly answers whether there is a subset of the input sequence whose sum is exactly . Show how to use the black box times to find a subset of that adds up to .
Solution
1fun test() {2 println(findSubset(listOf(3, 5, 8, 2, 1), 6))3 println(findSubset(listOf(2, 3, 5, 8, 6, 4), 20))4}56fun findSubset(s: List<Int>, k: Int): List<Int>? {7 if (!blackBox(s, k)) return null89 var subset = s10 for (i in s.indices) {11 val subsetWithoutIthNumber = subset.filter { it != s[i] }1213 if (blackBox(subsetWithoutIthNumber, k)) {14 subset = subsetWithoutIthNumber15 }16 }1718 return subset19}2021fun blackBox(integers: List<Int>, k: Int): Boolean {22 // We were not told to implement the black box, so we will hack it for the tests23 return if (k == 6) {24 integers.containsAll(listOf(1, 2, 3))25 } else return if (k == 20) {26 integers.containsAll(listOf(2, 8, 6, 4)) || integers.containsAll(listOf(3, 5, 8, 4))27 } else {28 throw IllegalArgumentException()29 }30}Let be an array of real numbers. Design an algorithm to perform any sequence of the following operations:
Add(i,y)– Add the value to the th number.Partial-sum(i)– Return the sum of the first numbers, that is, .
There are no insertions or deletions; the only change is to the values of the numbers. Each operation should take steps. You may use one additional array of size as a work space.
Solution
g
Extend the data structure of the previous problem to support insertions and deletions. Each element now has both a ''key'' and a ''value''. An element is accessed by its key, but the addition operation is applied to the values. The ''Partial_sum'' operation is different.
Add(k,y)– Add the value to the item with key .Insert(k,y)– Insert a new item with key and value .Delete(k)– Delete the item with key .Partial-sum(k)– Return the sum of all the elements currently in the set whose key is less than , that is, .
The worst-case running time should still be for any sequence of operations.
Solution
g
You are consulting for a hotel that has one-bed rooms. When a guest checks in, they ask for a room whose number is in the range . Propose a data structure that supports the following data operations in the allotted time:
Initialize(n): Initialize the data structure for empty rooms numbered , in polynomial time.Count(l, h): Return the number of available rooms in , in time.Checkin(l, h): In time, return the first empty room in and mark it occupied, or return NIL if all the rooms in are occupied.Checkout(x): Mark room as unoccupied, in time.
Solution
1fun test() {2 val ds = DataStructure()3 ds.initialize(10)4 println(ds.root)56 println("Available in [2, 5]: ${ds.count(2, 5)}")7 val checkIn1 = ds.checkIn(2, 5)8 println("Available in [2, 5]: ${ds.count(2, 5)}")9 val checkIn2 = ds.checkIn(2, 5)10 println("Available in [2, 5]: ${ds.count(2, 5)}")1112 ds.checkOut(checkIn2!!)13 println("Available in [2, 5]: ${ds.count(2, 5)}")14 ds.checkOut(checkIn2)15 ds.checkOut(checkIn1!!)16 println("Available in [2, 5]: ${ds.count(2, 5)}")17}1819class DataStructure() {2021 lateinit var root: BNode2223 fun initialize(n: Int) {24 root = sortedListToBinaryTree((1..n).toList())!!25 }2627 fun sortedListToBinaryTree(list: List<Int>): BNode? {28 if (list.isEmpty()) {29 return null30 }3132 val mid = list.size / 233 val root = BNode(list[mid])34 root.left = sortedListToBinaryTree(list.slice(0 until mid))35 root.right = sortedListToBinaryTree(list.slice((mid + 1) until list.size))3637 return root38 }3940 fun count(l: Int, h: Int): Int {41 return countInRange(l, h, root)42 }4344 fun checkIn(l: Int, h: Int): Int? {45 val first = findFirstInRange(l, h, root)46 first?.isCheckedIn = true47 return first?.element48 }4950 fun checkOut(x: Int) {51 find(x, root)?.isCheckedIn = false52 }5354 fun countInRange(l: Int, h: Int, node: BNode?): Int {55 if (node == null) {56 return 057 }5859 val count = if (node.element in l..h && !node.isCheckedIn) 1 else 06061 return if (node.element in l..h) {62 count + countInRange(l, h, node.left) + countInRange(l, h, node.right)63 } else if (node.element < l) {64 count + countInRange(l, h, node.right)65 } else {66 count + countInRange(l, h, node.left)67 }68 }6970 fun findFirstInRange(l: Int, h: Int, node: BNode?): BNode? {71 if (node == null) {72 return null73 }7475 if (node.element in l..h && !node.isCheckedIn) {76 return node77 }7879 return if (node.element < l) {80 findFirstInRange(l, h, node.right)81 } else if (node.element > h) {82 findFirstInRange(l, h, node.left)83 } else {84 findFirstInRange(l, h, node.left) ?: findFirstInRange(l, h, node.right)85 }86 }8788 fun find(x: Int, node: BNode?): BNode? {89 if (node == null) {90 return null91 }9293 return if (node.element == x) {94 node95 } else if (node.element < x) {96 find(x, node.right)97 } else {98 find(x, node.left)99 }100 }101}102103data class BNode(104 val element: Int,105 var isCheckedIn: Boolean = false,106 var left: BNode? = null,107 var right: BNode? = null,108)Design a data structure that allows one to search, insert, and delete an integer in time (i.e., constant time, independent of the total number of integers stored). Assume that and that there are units of space available, where is the maximum number of integers that can be in the table at any one time. (Hint: use two arrays and .) You are not allowed to initialize either or , as that would take or operations. This means the arrays are full of random garbage to begin with, so you must be very careful.
Solution
1fun test() {2 val ds = DataStructure(m = 5, n = 10)3 ds.insert(7)4 ds.insert(3)5 ds.insert(6)6 ds.insert(5)7 ds.insert(9)89 println(ds.search(6))10 println(ds.search(9))1112 ds.delete(6)13 ds.delete(9)1415 println(ds.search(6))16 println(ds.search(9))17}1819class DataStructure(20 val m: Int,21 val n: Int22) {2324 val indices = arrayOfNulls<Int>(n + 1)25 val values = arrayOfNulls<Int>(m + 1)26 var k = 02728 fun insert(x: Int) {29 k++30 indices[x] = k31 values[k] = x32 }3334 fun search(x: Int): Int? {35 val index = indices[x] ?: return null36 return values[index]37 }3839 fun delete(x: Int) {40 val xIndex = indices[x] ?: return41 if (k == 0) return4243 val lastValue = values[k]!!44 indices[lastValue] = xIndex45 values[xIndex] = lastValue46 values[k] = null47 indices[x] = null4849 k--50 }51}What method would you use to look up a word in a dictionary?
Solution
Use a hash table: Store the word as the key and the definition as the value.
Imagine you have a closet full of shirts. What can you do to organize your shirts for easy retrieval?
Solution
Sort them based on specific property like color.
Write a function to find the middle node of a singly linked list.
Solution
1fun test() {2 val node1 = Node("Elvis", null)34 val node2 = Node("Chidera", null)5 node1.next = node267 val node3 = Node("Nnajiofor", null)8 node2.next = node3910 val node4 = Node("Jollof", null)11 node3.next = node41213 val node5 = Node("List", null)14 node4.next = node51516 println(middleElement(node1))17}1819data class Node(20 val element: String,21 var next: Node?22)2324fun middleElement(head: Node): Node {25 var hare: Node? = head26 var tortoise: Node = head2728 while (hare?.next != null) {29 hare = hare.next?.next30 tortoise = tortoise.next!!31 }3233 return tortoise34}Write a function to determine whether two binary trees are identical. Identical trees have the same key value at each position and the same structure.
Solution
1fun test() {2 val s1 = BNode(3 element = 5,4 left = BNode(5 element = 3,6 left = null,7 right = null8 ),9 right = BNode(10 element = 7,11 left = null,12 right = null13 )14 )1516 val s2 = BNode(17 element = 10,18 left = BNode(19 element = 8,20 left = null,21 right = null22 ),23 right = BNode(24 element = 12,25 left = null,26 right = null27 )28 )2930 println(isIdentical(s1, s2))31 println(isIdentical(s1, s1))32 println(isIdentical(s2, s2))33}3435fun isIdentical(tree1: BNode?, tree2: BNode?): Boolean {36 if (tree1 == null || tree2 == null) {37 return tree1 == tree238 }3940 return tree1.element == tree2.element &&41 isIdentical(tree1.left, tree2.left) &&42 isIdentical(tree1.right, tree2.right)43}4445data class BNode(46 val element: Int,47 var left: BNode?,48 var right: BNode?,49)Write a program to convert a binary search tree into a linked-list.
Solution
See Problem 14: Part of the solution involves converting a tree into a linked-list.
Implement an algorithm to reverse a linked list. Now do it without recursion.
Solution
1fun test() {2 val node1 = Node("Elvis", null)34 val node2 = Node("Chidera", null)5 node1.next = node267 val node3 = Node("Nnajiofor", null)8 node2.next = node3910 println(reverse(node1))11}1213fun reverse(head: Node): Node {14 var currentNode: Node? = head15 var previousNode: Node? = null1617 while (currentNode != null) {18 val nextNode = currentNode.next19 currentNode.next = previousNode20 previousNode = currentNode21 currentNode = nextNode22 }2324 return previousNode!!25}2627data class Node(28 val element: String,29 var next: Node?30)
What is the best data structure for maintaining URLs that have been visited by a web crawler? Give an algorithm to test whether a given URL has already been visited, optimizing both space and time.
Solution
A dictionary that acts as a set:
- When a URL is visited, it's added to the dictionary.
- To check if a URL has been visited, check if the dictionary contains the URL as a key.
You are given a search string and a magazine. You seek to generate all the characters in the search string by cutting them out from the magazine. Give an algorithm to efficiently determine whether the magazine contains all the letters in the search string.
Solution
1fun test() {2 val node1 = Node("Elvis", null)34 println(containsAllCharacters("Elvis", "The Elfs are very happy"))5 println(containsAllCharacters("Elvis", "The Elfs are very happy because it is christmas"))6}78fun containsAllCharacters(string: String, magazine: String): Boolean {9 val map = mutableMapOf<Char, Int>()1011 string.forEach { char ->12 map[char] = map.getOrDefault(char, 0) + 113 }1415 var matched = 016 magazine.forEach { char ->17 val count = map[char] ?: 01819 if (count > 0) {20 matched++21 map[char] = count - 122 }2324 if (matched == string.length) {25 return true26 }27 }2829 return false30}Reverse the words in a sentence—that is, “My name is Chris” becomes “Chris is name My.” Optimize for time and space.
Solution
1fun test() {2 println(reverse("My name is Chris"))3}45fun reverse(sentence: String): String {6 val words = sentence.split(" ")7 var reversedSentence = ""89 var i = words.lastIndex10 while (i >= 0) {11 val word = words[i]12 reversedSentence += word13 i--1415 if (i >= 0) {16 reversedSentence += " "17 }18 }1920 return reversedSentence21}Determine whether a linked list contains a loop as quickly as possible without using any extra storage. Also, identify the location of the loop.
Solution
1fun test() {2 val node1 = Node("Elvis", null)34 val node2 = Node("Chidera", null)5 node1.next = node267 val node3 = Node("Nnajiofor", null)8 node2.next = node3910 val node4 = Node("Jollof", null)11 node3.next = node41213 val node5 = Node("List", null)14 node4.next = node51516 node5.next = node31718 println(detectLoopLocation(node1)?.element)19}2021data class Node(22 val element: String,23 var next: Node?24)2526/**27* https://en.wikipedia.org/wiki/Cycle_detection#:~:text=Floyd's%20cycle%2Dfinding%20algorithm%20is,The%20Tortoise%20and%20the%20Hare.28*/29fun detectLoopLocation(head: Node): Node? {30 var hare: Node? = head31 var tortoise: Node? = head3233 while (hare != null) {34 hare = hare.next?.next35 tortoise = tortoise?.next3637 if (hare == tortoise) {38 break39 }40 }4142 if (head.next != null && hare == tortoise) {43 hare = head44 while (hare != tortoise) {45 hare = hare?.next46 tortoise = tortoise?.next47 }4849 return tortoise!!50 }5152 return null53}
You have an unordered array of integers. Find the array containing elements where is the product of all integers in except for . You may not use division. You can use extra memory. (Hint: there are solutions faster than .)
Solution
1fun test() {2 println(transform(arrayOf(3, 5, 4)).toList())3 println(transform(arrayOf(2, 3, 4, 5, 6)).toList())4}56fun transform(x: Array<Int>): Array<Int> {7 val prefixProducts = Array(x.size) { 0 }8 val suffixProducts = Array(x.size) { 0 }910 var prefixProduct = 111 x.forEachIndexed { i, xi ->12 prefixProducts[i] = prefixProduct13 prefixProduct *= xi14 }1516 var suffixProduct = 117 var i = x.lastIndex18 while (i >= 0) {19 val xi = x[i]20 suffixProducts[i] = suffixProduct21 suffixProduct *= xi22 i--23 }2425 return Array(x.size) {26 prefixProducts[it] * suffixProducts[it]27 }28}Give an algorithm for finding an ordered word pair (e.g. “New York”) occurring with the greatest frequency in a given webpage. Which data structures would you use? Optimize both time and space.
Solution
1fun test() {2 println(findOrderedWordPairWithMaxFrequency("New york is a great city. I love new york."))3 println(findOrderedWordPairWithMaxFrequency("My name is Elvis Chidera. Elvis Chidera is me."))4}56/*7Punctuation marks can mess up the algorithm. Only "." is handled.8 */9fun findOrderedWordPairWithMaxFrequency(text: String): Pair<String, String> {10 val words = text.replace(".", "").split(" ")11 if (words.size <= 1) throw IllegalArgumentException("Text is empty or only has one word")1213 val wordPairs = mutableMapOf<Pair<String, String>, Int>()1415 var i = 116 while (i < words.size) {17 val previousWord = words[i - 1]18 val currentWord = words[i]19 val wordPair = previousWord to currentWord2021 wordPairs[wordPair] = wordPairs.getOrDefault(wordPair, 1) + 122 i++23 }2425 var maxFrequency = 026 var wordPairWithMaxFrequency: Pair<String, String>? = null27 wordPairs.forEach { (wordPair, frequency) ->28 if (frequency > maxFrequency) {29 maxFrequency = frequency30 wordPairWithMaxFrequency = wordPair31 }32 }3334 return wordPairWithMaxFrequency!!35}
Chaper 4: Sorting
This chapter discusses sorting, algorithm design paradigms espoused by sorting algorithms and how sorting can be applied in solving other problems.
Applications of sorting
The first algorithm design paradigm is the application of sorting as an initial step to simplify another computational problem. e.g.
- Searching – Preprocessing the search items by sorting them allows an efficient algorithm like binary search to be used.
- Closest pair – Once a set of numbers are sorted, the closest pair of numbers must lie next to each other somewhere in sorted order. Thus, a linear-time scan through the sorted list completes the job, for a total of time including the sorting.
- Element uniqueness – An efficient algorithm sorts the elements and then does a linear scan checking all adjacent pairs.
- Finding the mode – When the items are sorted, we can sweep from left to right and count the number of occurrences of each element, since all identical items will be adjacent to each other after sorting,
- Selection – If the keys are placed in sorted order, the kth largest item can be found in constant time because it must sit in the kth position of the array.
Sorting pragmatics
Pairwise comparison (i.e. is or or to ) is typical abstracted away into a comparison function that is then passed to the sorting algorithm. This allows the sorting algorithm to be independent of application-specific comparison concerns like:
- Alphabetizing – A collating sequence (also called a sort sequence) defines how characters in a character set relate to each other when they are compared and ordered. This can vary from usecase to usecase, e.g. should "Elvis" be equivalent to "elvis"?
- Arbitrary elements – What properties of the element should be used as the key for comparisons?
- Sort order – A set of keys are sorted in ascending order when for all . They are in descending order when for all . Different applications call for different orders and this can be handled by only changing the comparison function.
- Handling equal elements – Elements with equal key values all bunch together in any total order. When the relative order among these keys matters, a common strategy is to sort the equal elements using a secondary key, which can be handled easily with the comparison function.
An example comparison function:
1/**2* Returns a negative integer if `e1` is less than `e2`.3* Returns zero if `e1` is equal `e2`.4* Returns a positive integer if `e1` is greater than `e2`.5*/6fun compare(e1: Element, e2: Element): Int {78}Stable sorting algorithms maintain the relative order of elements with equal keys. That is, a sorting algorithm is stable if whenever there are two elements and with the same key and with appearing before in the original list, will appear before in the sorted list.
Few fast algorithms are naturally stable. Stability can be achieved for any sorting algorithm by adding the initial position as a secondary key.
When equal elements are indistinguishable, such as with integers, or more generally, any data where the entire element is the key, stability is not an issue.
Heap: Data structure
A heap is a tree-based data structure that satisfies the heap property:
- In a max heap, for any given node , if is a parent node of , then the key (the value) of is greater than or equal to the key of .
- In a min heap, the key of is less than or equal to the key of .
The heap is one maximally efficient implementation of a priority queue ADT. In a heap, the highest (or lowest) priority element is always stored at the root. A heap is a useful data structure when it is necessary to repeatedly remove the object with the highest (or lowest) priority.
However, a heap is not a sorted structure; it can be regarded as being partially ordered: there is no implied ordering between siblings or cousins and no implied sequence for an in-order traversal. The heap relation mentioned above applies only between nodes and their parents, grandparents, etc.
Implementation
Heaps are usually implemented with an array:
- Each element in the array represents a node of the heap, and
- The parent / child relationship is defined implicitly by the elements' indices in the array. This implicit structure is space efficient as it eliminates the need for pointers to give an explicit relationship between elements.
For a binary heap, in the array:
- The first index contains the root element.
- The next two indices of the array contain the root's children.
- The next four indices contain the four children of the root's two child nodes, and so on.
This can be generalized into:
Given a node at index ,
Its left child is at index
Its right child is at index
And its parent is at index
This simple indexing scheme makes it efficient to move "up" or "down" the tree.
This implicit structure trades space efficiency for flexibility. e.g. With pointers, we can move subtrees around by changing a single pointer.
To avoid potentially requiring a array to store an -element heap, it's required that the binary heap is complete with its element inserted from left to right. This structural constraint allows us to store the -element heap with the first indices of the array. When a heap is a complete binary tree, it has the smallest possible height — a heap with nodes and branches for each node always has height.

1/**2 * Put elements of [array] in heap order, in-place.3 *4 * Consider the array in reverse order, starting from the last (nth) position. It represents a leaf of the tree and5 * so trivial obeys the heap property (i.e. it's larger than its non-existent children). The same is the case for6 * the last n/2 positions in the array, because all are leaves.7 *8 * If we continue to walk backwards through the array we will eventually encounter an internal node with children.9 * This element may not obey the heap property (because it might be smaller than its children),10 * but its children represent well-formed (if small) heaps. This situation is exactly what [siftDown] was designed11 * to do: given a "damaged" binary heap, where the max-heap property (no child is greater than its parent) holds12 * everywhere except possibly between the root node and its children, repair it to produce an undamaged heap.13 *14 * To see that this takes O(n) time, count the worst-case number of [siftDown] iterations.15 * The last half of the array requires zero iterations, the preceding quarter requires at most one iteration,16 * the eighth before that requires at most two iterations, the sixteenth before that requires at most three, and so on.17 */18private fun heapify(array: ArrayList<Int>) {19 // Start is initialized to the first leaf node20 // Find the parent of the last element.21 var start = iParent(array.lastIndex) + 12223 while (start > 0) {24 // Go to the last non-heap node25 start -= 126 // Sift down the node at index 'start' to the proper place such that all nodes below the start index are in heap order27 siftDown(array, start, array.lastIndex)28 }2930 // After sifting down the root all nodes/elements are in heap order.31}3233private fun siftUp(array: ArrayList<Int>, index: Int) {34 var index = index3536 while (index > 0) {37 val parentIndex = iParent(index)3839 if (array[parentIndex] < array[index]) {40 swap(array, parentIndex, index)41 index = parentIndex42 } else {43 return44 }45 }46}4748/**49 * Repair the heap whose root element is at index 'start', assuming the heaps rooted at its children are valid.50 *51 * The number of iterations in any one [siftDown] call is bounded by the height of the tree, which is ⌊log2 n⌋ = O(log n).52 */53fun siftDown(array: ArrayList<Int>, rootIndex: Int, endIndex: Int) {54 var rootIndex = rootIndex55 while (iLeftChild(rootIndex) <= endIndex) { // While the root has at least one child56 var biggerChildIndex = iLeftChild(rootIndex)5758 // If there is right child and that child is greater59 if (iRightChild(rootIndex) <= endIndex && array[biggerChildIndex] < array[iRightChild(rootIndex)]) {60 biggerChildIndex = iRightChild(rootIndex)61 }6263 if (array[rootIndex] < array[biggerChildIndex]) {64 swap(array, rootIndex, biggerChildIndex)65 rootIndex = biggerChildIndex66 // Repeat to continue sifting down the child now.67 } else {68 // The root holds the largest element. Since we may assume the heaps rooted at the children are valid,69 // this means that we are done.70 return71 }72 }73}7475private fun swap(array: ArrayList<Int>, i: Int, j: Int) {76 val temp = array[i]77 array[i] = array[j]78 array[j] = temp79}8081fun iParent(i: Int): Int {82 return floor(i / 2.0).toInt()83}8485fun iLeftChild(i: Int): Int {86 return (i * 2) + 187}8889fun iRightChild(i: Int): Int {90 return (i * 2) + 291}9293data class Heap(private val array: ArrayList<Int>) {9495 init {96 heapify(array)97 }9899 /**100 * Add the new element at the end of the heap, in the first available free space.101 * If this violates the heap property, sift up the new element until the heap property has been reestablished.102 * Since the heap is balanced, the height is $log_2 n$ and hence each insertion costs at most $O(log_2 n)$.103 */104 fun insert(element: Int) {105 array.add(element)106 siftUp(array, array.lastIndex)107 }108109 /**110 * Remove the root and insert the last element of the heap in the root.111 * If this violates the heap property, sift down the new root to reestablish the heap property.112 */113 fun pop(): Int {114 val root = array[0]115 val lastChild = array.removeLast()116 array[0] = lastChild117 siftDown(array, 0, array.lastIndex)118 return root119 }120121 /**122 * Remove the root and put the new element in the root and sift down.123 * When compared to pop followed by insert, this avoids a sift up step.124 */125 fun replaceRoot(element: Int) {126 array[0] = element127 siftDown(array, 0, array.lastIndex)128 }129}Heapsort: Fast sorting via data structures
Heapsort is an in-place comparison-based sorting algorithm which can be thought of as "an implementation of selection sort using the right data structure." Like selection sort, heapsort divides its input into a sorted and an unsorted region, and it iteratively shrinks the unsorted region by extracting the largest element from it and inserting it into the sorted region. Unlike selection sort, heapsort does not waste time with a linear-time scan of the unsorted region; rather, heap sort maintains the unsorted region in a heap data structure to efficiently find the largest element in each step.
Although somewhat slower in practice on most machines than a well-implemented quicksort, it has the advantages of very simple implementation and a more favorable worst-case runtime. Most real-world quicksort variants include an implementation of heapsort as a fallback should they detect that quicksort is becoming degenerate.
Heapsort is an example of the second algorithm design paradigm: Use an appropriate data structure.
1/**2 * The steps are:3 *4 * 1. Call the [heapify] function on the array. This builds a heap from an array in O(n) operations.5 * 2. Swap the first element of the array (the largest element in the heap) with the final element of the heap. Decrease the considered range of the heap by one.6 * 3. Call the [siftDown] function on the array to move the new first element to its correct place in the heap.7 * 4. Go back to step (2) until the remaining array is a single element.8 *9 * The [heapify] operation is run once, and is O(n) in performance.10 * The [siftDown] function is called n times and requires O(log n) work each time, due to its traversal starting from the root node.11 * Therefore, the performance of this algorithm is O(n + n log n) = O(n log n).12 */13fun heapsort(array: ArrayList<Int>): ArrayList<Int> {14 // Build the heap in the array so that largest value is at the root15 heapify(array)16 var endIndex = array.lastIndex1718 // The following loop maintains the invariants that every element between 0 to endIndex is a heap, and19 // every element beyond endIndex is greater than everything before it (in sorted order).20 while (endIndex > 0) {21 // [0] is the root and largest value. The swap moves it in front of the sorted elements.22 swap(array, 0, endIndex)23 // The heap size is reduced by one.24 endIndex--25 // The swap ruined the heap property, so restore it.26 siftDown(array, 0, endIndex)27 }2829 return array30}